What Is A Regular Expression:
A Regular Expression, or Regex for short, is a string of text that allows us to manage, match, filter and extract text.
Regex is particularly useful in digital marketing where it’s often necessary to extract specific pieces of useful data from large data sets.
Extracting this useful data can be a cumbersome task when completed manually, often requiring significant time. With Regex, we can use formulae to simplify and speed up these tasks.
Whilst Regex can appear daunting or intimidating at first, this blog should demonstrate how simple Regex can be, and help encourage other marketers to make a start on eliminating and automating the most boring and time-consuming parts of data analysis.
Common Tokens:
A Regular Expression consists of tokens. Each of these tokens matches a single character or series of characters within your data set or determine the position in which a character must be. We can see some examples of the most commonly used tokens in the table below.
| Token | Function |
| | | Alternate, either/or. “A|B” matches with, both “A” and “B”. |
| . | Matches with any single character other than a new line. |
| * | Matches zero or more than. So “.*” matches with zero or more of any character other than a new line. |
| + | Matches one or more than. So “.+” matches with one or more of any character other than a new line. |
| ? | Matches zero or one time. So “.?” matches if there are zero or one of any character other than a new line. |
| \ | Matches the following character literally. So “\.” matches with only “.” and no other characters. |
| (…) | Rounded brackets denote a capture group. Everything within the rounded brackets is captured. |
| (?:…) | Rounded brackets followed by a “?:” denotes a non-capture group. This is similar to a capture group but the content isn’t retained. |
| {…} | Curly brackets determine how many instances of the previous token you would like to match. For example, “(a{1,3})” will match between 1 and 3 instances of the letter “a”. |
| […] | Square brackets allow us to define ranges or different characters or tokens to be matched. For example, “[A-z]” matches any upper or lower case letter. |
| ^ | A “^” matches the start of a string, or when used inside square brackets means characters not in a range. For example [^A-z] will not match with any lower case or upper case letters. |
| $ | A “$” matches the end of a string. For example, “[A-z]$” will match with an upper or lower case letter when it is found at the end of the string. |
| \s | “\s” matches with any whitespace character. |
| \S | “\S” matches with any non-whitespace character. |
| \d | “\d” matches with any digit character. |
| \D | “\D” matches with any non-digit character. |
| \w | “\w” matches with any letter, digit, or underscore. |
| \W | “\W” matches with anything other than a letter, digit, or underscore. |
Examples of Useful Applications for Regex in Digital Marketing:
Screaming Frog
In Screaming Frog we can perform custom extractions using Regex. Custom extractions allow us to extract tons of useful information from a website.
Some examples of data we can extract include; Email addresses, tracking IDs, Schema Markup, Page Titles, URLs, and tons more. If you can think of it, you can probably use Regex to find it!
In the image below we can see an example of a Regex used to find email addresses. This can be useful, as having email addresses in plain text on your website can be a security vulnerability and result in email addresses being scraped.
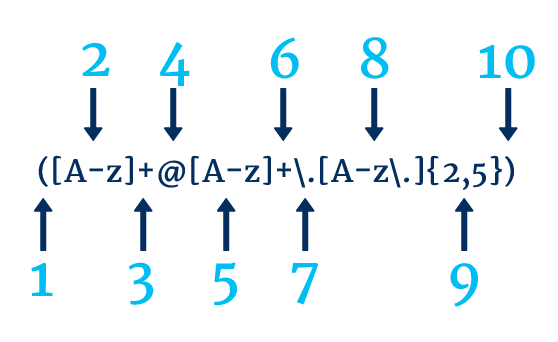
- Step 1 shows the beginning of the capture group
- Step 2 matches any upper case letters, lower case letters, or underscores
- Step 3 tells us we are looking for 1 or more instances of step 2
- Step 4 matches with the @
- Step 5 matches any upper case letters, lower case letters, or underscores
- Step 6 tells us we are looking for 1 or more instances of step 5
- Step 7 matches with a period, we must use a \ so we match with the period literally, and not the “.” function
- Step 8 matches with any upper case letters, lower case letters, underscores, or periods
- Step 9 tells us we are looking for between 2 and 5 occurrences of step 8
- Step 10 shows the closing of the capture group
If we do a custom extraction of screaming frog using the Codefixer website and run a crawl we can then see any of the email addresses that appear on the website.

Google Analytics
Google Analytics allows us to use Regex for a number of applications such as; filtering views, creating goals, creating audiences, content grouping, and channel grouping.
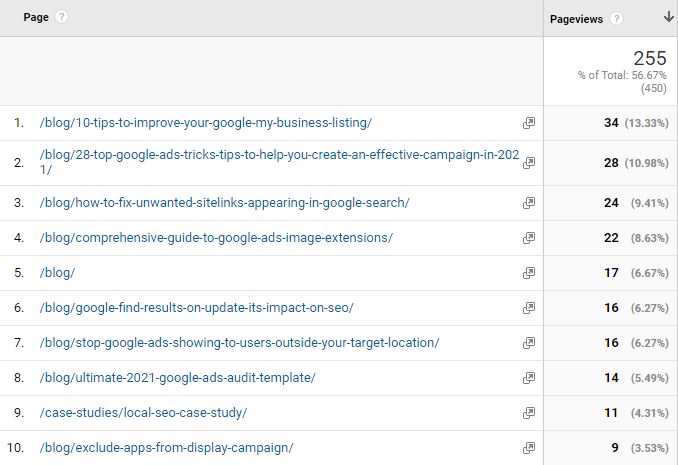
In the example below we can see an example of Regex used on Google Analytics to filter to only show pageviews for either blog or case study pages. Admittedly this is a bit overkill, you could just use (blog|case), but this gives a better demonstration as to how it works.

- Step 1 shows the beginning of the capture group
- Step 2 means that this must be the beginning of the string
- Step 3 matches with a “/”. We use the “\” before the forward-slash to match with exactly that character literally
- Step 4 matches with the word “blog”
- Step 5 matches with any character except a new line one or more times
- Step 6 means we need to match with something before or after the vertical bar
- Step 7 means that this must be the beginning of the string
- Step 8 matches with a “/”. We use the “\” before the forward-slash to match with exactly that character literally
- Step 9 matches with the word “case”
- Step 10 matches with any character except a new line one or more times
- Step 11 shows the closing of the capture group
When we filter our Google Analytics view, we can now see that we are only seeing page-views for our pages that are in the blog or case studies sub-folders.
Google Tag Manager
On Google Tag Manager we can use Regex to trigger Google Analytics Events when a user completes an action.
One thing we can track using Google Tag Manager is users clicking a telephone number on the website.
Occasionally, on a website, tracking simple events such as telephone number clicks can be complicated by formatting or variations of the telephone number appearing on the website.
This complicates the process of being able to create a tag in Google Tag Manager to trigger an event when a telephone number is clicked due to it not being in a consistent format, meaning we can not simply set this trigger to fire when the Click URL contains “tel:02890 923383”.
Let’s say we have the Codefixer telephone number links on the website in three different forms;
- tel:02890923383
- tel:028 90 923383
- tel:(+44) 2890 923383
We can use the following Regex to match with all three of the telephone numbers above.
![]()
![]()
- Step 1 shows the beginning of the non-capture group “(?:”
- Step 2 will match with “tel:”
- Step 3 opens the first capture group
- Step 4 matches with “028” at the beginning of the telephone numbers where this is applicable
- Step 5 means “or”, so we can match with the first or the next set of characters
- Step 6 matches with “(+44)”. The “\” is to escape the special characters +, (, and )
- Step 7 closes the capture group
- Step 8 matches if there are zero or one whitespace character
- Step 9 matches with any character between 0-9
- Step 10 matches if there are zero or one whitespace character
- Step 11 matches with 1 or more of the previous steps and finally closes the non-capture group
How To Learn Regex:
Whilst the above guide provides an introduction, some examples, and practical applications for Regex, I’ll be first to admit that I’m by no means an expert, and reading a blog post is probably not going to make you an expert all of a sudden.
The main way to get better Regex is by rolling up your sleeves and practising your skills on a regular basis.
As part of my role as PPC Lead in Codefixer, I’ve started using Regex regularly to simplify and automate simple tasks, and as time has progressed, I’ve begun using it in more complex or complicated situations which have helped to improve my understanding and uses for Regex.
There are a ton of fantastic free resources online for learning Regex. The main three websites that I have found most useful are:
- https://regex101.com/ – A fantastic website for building, testing & debugging your Regex. I usually always have a tab open on my browser with Regex101 open. This is an absolute lifesaver when you just can’t quite figure out how to do something!
- https://regexone.com – Regexone is a website with easy to follow and informative, enjoyable exercises to help you learn and use Regex. The tasks begin quite easy, but quickly progress to become more challenging. Ideal for beginners.
- https://www.sitepoint.com/learn-regex/ – This Sitepoint blog explains Regex in very simple and easy to understand terms. Whilst you probably won’t need this every day, it’ll always have a place on my bookmark bar as a great resource for beginners.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}